Искусственный интеллект активно проникает во все аспекты нашей жизни. В сфере электронной коммерции ИИ предоставляет множество возможностей для оптимизации бизнес-процессов.
В данной статье мы рассмотрим успешные примеры применения искусственного интеллекта для прогнозирования продаж.
Многие современные пользователи, услышав о искусственном интеллекте, в первую очередь думают о языковых моделях, таких как ChatGPT, YandexGPT или Gigachat. Однако эта технология гораздо более многогранна и разнообразна, чем может показаться на первый взгляд, открывая перед нами поистине безграничные перспективы.
В данной статье мы рассмотрим успешные примеры применения искусственного интеллекта для прогнозирования продаж.
Многие современные пользователи, услышав о искусственном интеллекте, в первую очередь думают о языковых моделях, таких как ChatGPT, YandexGPT или Gigachat. Однако эта технология гораздо более многогранна и разнообразна, чем может показаться на первый взгляд, открывая перед нами поистине безграничные перспективы.
Маркетплейсы уже активно используют искусственный интеллект в своих сервисах. Например, OZON предлагает возможность создания видеообложек с помощью ИИ.

Интерфейс личного кабинета для создания видеообложек товаров с использованием искусственного интеллекта.
Яндекс Маркет предлагает автоматическое создание описаний товаров с использованием собственной языковой модели YandexGPT.
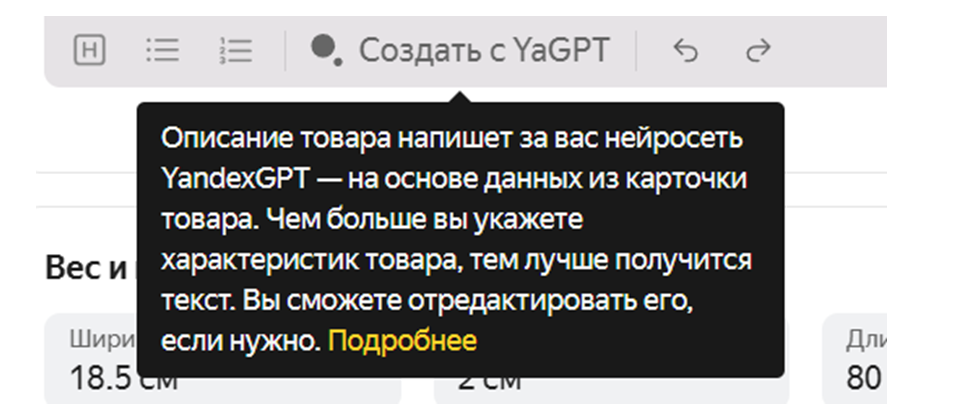
Интерфейс для создания описаний с использованием YandexGPT в кабинете продавца на Яндекс Маркет.
Wildberries применяет поиск по изображениям и предлагает помощь в создании описаний для продукции.
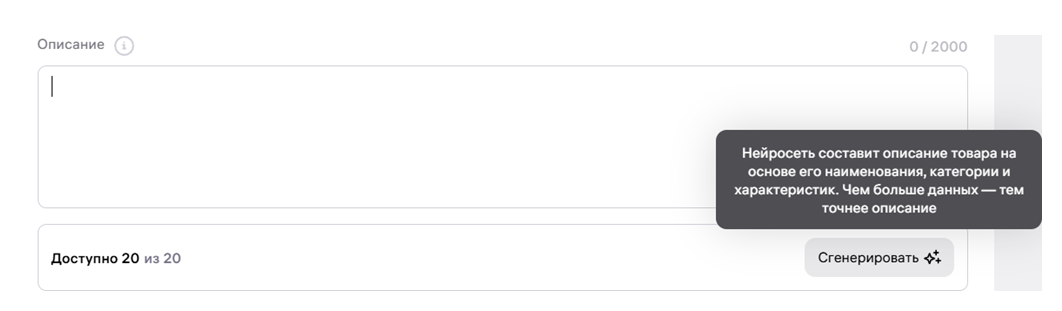
Генерация описаний с использованием искусственного интеллекта на Wildberries.

Кроме того, искусственный интеллект предлагает покупателям релевантные товары на основе их интересов, что активно используется всеми упомянутыми игроками. Сторонние сервисы позволяют автоматически отвечать на отзывы, создавая впечатление индивидуального подхода к каждому клиенту.
ак использовать ИИ для прогнозирования продаж
В этой статье мы с помощью методов машинного обучения рассчитаем прогноз продаж ранее не представленной в магазине туши для ресниц. Мы возьмем данные с MPstats ближайшего конкурента в аналогичном ценовом сегменте и дополним таблицу индексом популярности запроса из Яндекс Вордстат.
Возникает вопрос: чем данный подход отличается от прогнозов, предлагаемых сервисами вроде MPStats? Главное отличие заключается в том, что мы можем учитывать любые факторы, важные для нашего бизнеса, такие как сезонность, внешние факторы и текущие тренды.
В своей модели я буду учитывать:
1. Подготовка к работе
Для построения прогноза мы будем использовать язык программирования Python. Если у вас его еще нет, скачайте версию 3.11 с официального сайта. Также нам понадобится удобная среда разработки. Я предпочитаю PyCharm, которую можно бесплатно скачать и установить с официального сайта.
2. Выбор метода прогнозирования
Существует множество методов прогнозирования временных рядов, но в этой статье мы сосредоточимся на модели ARIMA/SARIMA. Также популярны методы XGBoost, LightGBM, Prophet и CatBoost (разработанный Яндексом). Каждый из них имеет свои преимущества и области применения, но для небольшого объема данных ARIMA является наиболее подходящей.
3. Переменные для модели
В нашем прогнозе мы будем использовать следующие переменные:
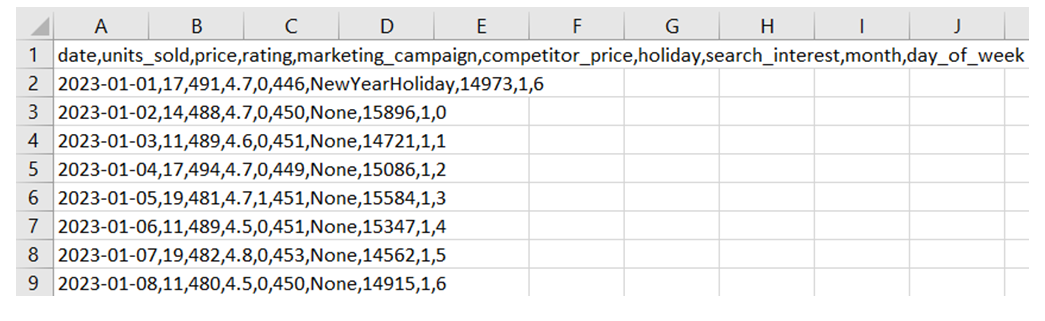
Важно, чтобы данные были сохранены в формате CSV с разделителем-запятой, чтобы обеспечить корректную обработку нейросетью.
Подготовленные данные будут выглядеть следующим образом:
В этой статье мы с помощью методов машинного обучения рассчитаем прогноз продаж ранее не представленной в магазине туши для ресниц. Мы возьмем данные с MPstats ближайшего конкурента в аналогичном ценовом сегменте и дополним таблицу индексом популярности запроса из Яндекс Вордстат.
Возникает вопрос: чем данный подход отличается от прогнозов, предлагаемых сервисами вроде MPStats? Главное отличие заключается в том, что мы можем учитывать любые факторы, важные для нашего бизнеса, такие как сезонность, внешние факторы и текущие тренды.
В своей модели я буду учитывать:
- Сезонность
- Динамику поисковых запросов
- Тренды рынка
1. Подготовка к работе
Для построения прогноза мы будем использовать язык программирования Python. Если у вас его еще нет, скачайте версию 3.11 с официального сайта. Также нам понадобится удобная среда разработки. Я предпочитаю PyCharm, которую можно бесплатно скачать и установить с официального сайта.
2. Выбор метода прогнозирования
Существует множество методов прогнозирования временных рядов, но в этой статье мы сосредоточимся на модели ARIMA/SARIMA. Также популярны методы XGBoost, LightGBM, Prophet и CatBoost (разработанный Яндексом). Каждый из них имеет свои преимущества и области применения, но для небольшого объема данных ARIMA является наиболее подходящей.
3. Переменные для модели
В нашем прогнозе мы будем использовать следующие переменные:
- date: дата продажи
- product_id: идентификатор продукта (название, артикул и т.д.)
- category: категория товара (например, тушь для ресниц)
- units_sold: количество проданных единиц (наш главный показатель)
- price: цена товара на дату продажи
- rating: средний рейтинг товара по отзывам на момент продажи
- marketing_campaign: индикатор (0 или 1), показывающий, была ли маркетинговая акция (реклама, скидки, email-рассылка)
- competitor_price: средняя цена основного конкурента или в категории
- holiday: праздничный или особый день (например, "NewYearHoliday"), "None" — если праздника нет
- wordstat: индекс популярности поискового запроса
- month: месяц
- day_of_week: день недели
Важно, чтобы данные были сохранены в формате CSV с разделителем-запятой, чтобы обеспечить корректную обработку нейросетью.
Подготовленные данные будут выглядеть следующим образом:
4. Лаговые переменные
Дополнительно можно использовать лаговые переменные:
Дополнительно можно использовать лаговые переменные:
- units_sold_lag_1, units_sold_lag_7, units_sold_lag_30: продажи за предыдущие периоды.
- Лаговые признаки для других переменных (например, прошлые значения wordstat).
- Откройте PyCharm и создайте новый проект.
- Создайте новый Python-файл.
6. Установка необходимых библиотек
В терминале, который открывается внизу PyCharm, установите следующие библиотеки:
7. Анализ временного ряда, загрузка и подготовка данных
Начнем с анализа временного ряда.
Рассмотрим каждую строку кода подробно:
python
df = pd.read_csv("sales_data_year.csv") # Загрузка данных из CSV-файла. Обратите внимание, что я назвал файл sales_data_year.csv. Если у вас другой файл, используйте его имя.
df['date'] = pd.to_datetime(df['date']) # Преобразование колонки 'date' в формат даты.
df = df.set_index('date') # Установка 'date' в качестве индекса DataFrame.
df = df.sort_index() # Сортировка данных по дате.
series = df['units_sold'] # Извлечение временного ряда (колонка 'units_sold').
После этого запустите написанный скрипт и посмотрите на визуальный результат. Мы увидим, что график успешно построен:
В терминале, который открывается внизу PyCharm, установите следующие библиотеки:
- pandas для работы с табличными данными: pip install pandas
- matplotlib для визуализации данных: pip install matplotlib
- numpy для математических операций: pip install numpy
- statsmodels для статистического моделирования: pip install statsmodels
- pmdarima для автоматического подбора параметров ARIMA: pip install pmdarima
7. Анализ временного ряда, загрузка и подготовка данных
Начнем с анализа временного ряда.
Рассмотрим каждую строку кода подробно:
python
df = pd.read_csv("sales_data_year.csv") # Загрузка данных из CSV-файла. Обратите внимание, что я назвал файл sales_data_year.csv. Если у вас другой файл, используйте его имя.
df['date'] = pd.to_datetime(df['date']) # Преобразование колонки 'date' в формат даты.
df = df.set_index('date') # Установка 'date' в качестве индекса DataFrame.
df = df.sort_index() # Сортировка данных по дате.
series = df['units_sold'] # Извлечение временного ряда (колонка 'units_sold').
После этого запустите написанный скрипт и посмотрите на визуальный результат. Мы увидим, что график успешно построен:
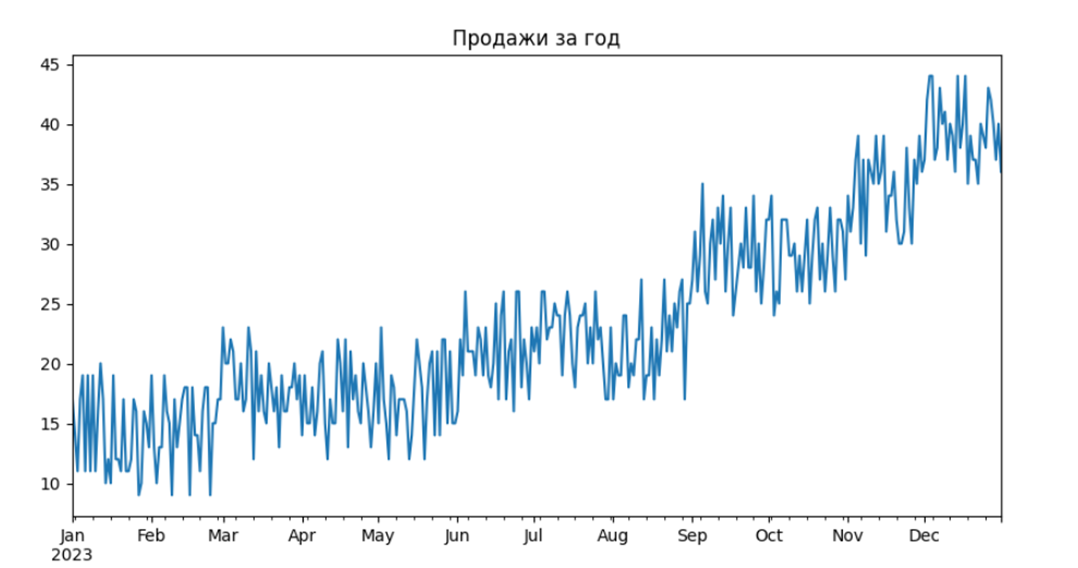
python
Копировать код
series.plot(figsize=(10, 5)) # Построение графика временного ряда
plt.title("Продажи за год") # Добавление заголовка
plt.show()
Визуализация помогает понять структуру данных: наличие трендов, сезонности или других паттернов.
Далее нам нужно применить дифференцирование.
Дифференцирование (вычисление разности между значениями) используется для сглаживания тренда и превращения ряда в стационарный. В начале статьи я упоминал, чем данный метод обучения локальной модели может быть лучше инструментов прогнозирования MPStats — это работа с трендами, сезонами и другими переменными, которые влияют на наши продажи.
python
series_diff = series.diff().dropna().diff().dropna() # Двойное дифференцирование (первая разность дважды)
Далее необходимо провести тест Дики-Фуллера на стационарность. Для этого используем следующий код:
python
result = adfuller(series)
print("ADF Statistic:", result[0])
print("p-value:", result[1])
Данный тест позволяет получить параметр p-value. Если p-value < 0.05, ряд считается стационарным (тренда нет). Если же p-value выше, как в нашем случае, это указывает на наличие тренда, так как существует множество переменных.

Теперь необходимо провести корреляцию временного ряда с его лагами (ACF). Напомним, что лаговые показатели являются одной из причин выбора метода ARIMA, а PACF показывает прямую (частичную) корреляцию, исключая влияние промежуточных лагов.
Эти графики помогают выбрать параметры p и q для модели ARIMA. Что такое P и Q, мы расскажем далее.
Эти графики помогают выбрать параметры p и q для модели ARIMA. Что такое P и Q, мы расскажем далее.
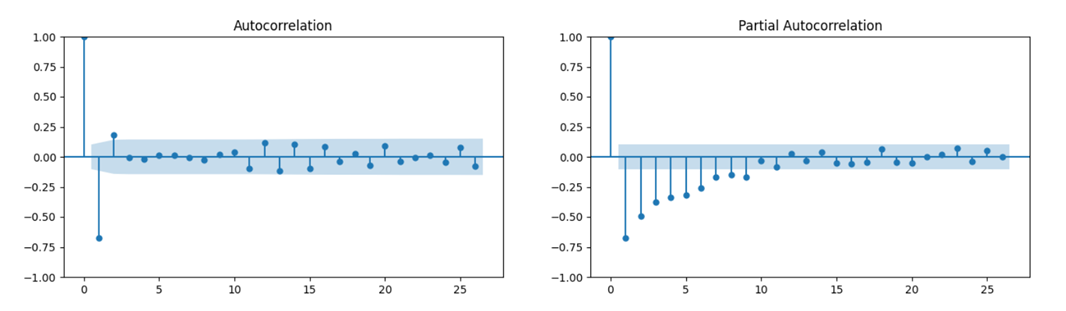
Следующий код выполняет автоматический подбор модели ARIMA (auto_arima):
python
stepwise_model = auto_arima(series, start_p=1, start_q=1,
max_p=5, max_q=5, m=7, # m=7 предполагает недельную сезонность
start_P=0, seasonal=False,
d=1, D=0, trace=True,
error_action='ignore',
suppress_warnings=True,
stepwise=True)
print(stepwise_model.summary())
Расшифровка параметров:
В конце выводится лучшая модель ARIMA с оптимальными параметрами (например, ARIMA(0,1,1)). В нашем случае мы получили следующий результат:
python
stepwise_model = auto_arima(series, start_p=1, start_q=1,
max_p=5, max_q=5, m=7, # m=7 предполагает недельную сезонность
start_P=0, seasonal=False,
d=1, D=0, trace=True,
error_action='ignore',
suppress_warnings=True,
stepwise=True)
print(stepwise_model.summary())
Расшифровка параметров:
- start_p=1, start_q=1: Начальные значения для параметров p и q.
- max_p=5, max_q=5: Максимальные значения для p и q.
- m=7: Указывает на недельную сезонность (если сезонность включена).
- seasonal=False: Отключена сезонная составляющая (для несезонных рядов).
- d=1: Порядок интегрирования (первая разность).
- trace=True: Показывает процесс подбора модели.
- suppress_warnings=True: Подавляет предупреждения.
В конце выводится лучшая модель ARIMA с оптимальными параметрами (например, ARIMA(0,1,1)). В нашем случае мы получили следующий результат:

Теперь построим модель обучения, используя следующий код:
python
model = ARIMA(series, order=(0, 1, 1))
ARIMA — это функция из библиотеки statsmodels для создания модели ARIMA (Autoregressive Integrated Moving Average).
order=(0, 1, 1) — это кортеж, который задает параметры модели ARIMA:
Таким образом, ARIMA(0,1,1) — это модель, которая работает с первой разностью временного ряда и одной компонентой скользящего среднего.
После этого перейдем к обучению модели:
python
model_fit = model.fit()
Метод fit() выполняет обучение модели на временном ряде series. На выходе получается объект model_fit, который содержит все параметры модели, ее характеристики и обученные коэффициенты. Во время обучения ARIMA подбирает оптимальные значения для коэффициентов MA(1) и других параметров.
Выведем результат нашей модели:
python
print(model_fit.summary())
model_fit.summary() выводит подробный отчет о модели, который включает:
Теперь приступаем к прогнозированию:
python
forecast = model_fit.forecast(steps=365)
forecast(steps=365) выполняет прогноз на 365 шагов вперед. В случае дневных данных это означает прогноз на 365 дней. Возвращаемый объект forecast — это массив прогнозируемых значений.
Что происходит в целом:
Таким образом, итоговый код обучения модели будет выглядеть следующим образом:
python
Копировать код
model = ARIMA(series, order=(0, 1, 1))
model_fit = model.fit()
print(model_fit.summary())
forecast = model_fit.forecast(steps=365)
Построим график прогноза и сохраним модель для дальнейшего использования:
python
plt.figure(figsize=(12, 6))
future_dates = pd.date_range(start='2024-01-01', periods=365, freq='D')
plt.plot(future_dates, forecast, label='Улучшенный прогноз', color='blue')
plt.legend()
plt.grid()
plt.title("Прогноз с улучшенными параметрами")
plt.show()
model_fit.save("arima_model.pkl")
plt.figure() создает новый график с указанным размером (ширина 12, высота 6).
pd.date_range() генерирует последовательность дат:
plt.plot() строит линию прогноза на графике:
plt.legend() добавляет легенду на график, чтобы различать разные линии.
plt.grid() включает сетку на графике для лучшей читаемости.
plt.title("Прогноз с улучшенными параметрами") добавляет заголовок к графику
python
model = ARIMA(series, order=(0, 1, 1))
ARIMA — это функция из библиотеки statsmodels для создания модели ARIMA (Autoregressive Integrated Moving Average).
order=(0, 1, 1) — это кортеж, который задает параметры модели ARIMA:
- p=0: Порядок авторегрессии (AR). Указывает, сколько предыдущих значений используется для предсказания. Здесь p=0, что означает отсутствие AR-компоненты.
- d=1: Порядок интегрирования. Означает, что применяется первая разность данных для сглаживания тренда и достижения стационарности ряда.
- q=1: Порядок компоненты скользящего среднего (MA). Модель учитывает одну ошибку предыдущего прогноза.
Таким образом, ARIMA(0,1,1) — это модель, которая работает с первой разностью временного ряда и одной компонентой скользящего среднего.
После этого перейдем к обучению модели:
python
model_fit = model.fit()
Метод fit() выполняет обучение модели на временном ряде series. На выходе получается объект model_fit, который содержит все параметры модели, ее характеристики и обученные коэффициенты. Во время обучения ARIMA подбирает оптимальные значения для коэффициентов MA(1) и других параметров.
Выведем результат нашей модели:
python
print(model_fit.summary())
model_fit.summary() выводит подробный отчет о модели, который включает:
- Параметры модели (например, MA(1)).
- Стандартные ошибки параметров.
- Критерии качества модели: AIC (Akaike Information Criterion), BIC и другие метрики.
- Логарифм правдоподобия (LogLikelihood).
- Остатки модели и тесты на автокорреляцию остатков.
Теперь приступаем к прогнозированию:
python
forecast = model_fit.forecast(steps=365)
forecast(steps=365) выполняет прогноз на 365 шагов вперед. В случае дневных данных это означает прогноз на 365 дней. Возвращаемый объект forecast — это массив прогнозируемых значений.
Что происходит в целом:
- Создается модель ARIMA с параметрами (0, 1, 1), где:
- Применяется первая разность для сглаживания тренда (d=1).
- Используется скользящее среднее первого порядка (q=1).
- Модель обучается на предоставленных данных (series).
- Выводится сводка параметров модели, включая метрики качества (AIC, BIC и др.).
- Модель делает прогноз на 365 шагов вперед (например, на 1 год).
Таким образом, итоговый код обучения модели будет выглядеть следующим образом:
python
Копировать код
model = ARIMA(series, order=(0, 1, 1))
model_fit = model.fit()
print(model_fit.summary())
forecast = model_fit.forecast(steps=365)
Построим график прогноза и сохраним модель для дальнейшего использования:
python
plt.figure(figsize=(12, 6))
future_dates = pd.date_range(start='2024-01-01', periods=365, freq='D')
plt.plot(future_dates, forecast, label='Улучшенный прогноз', color='blue')
plt.legend()
plt.grid()
plt.title("Прогноз с улучшенными параметрами")
plt.show()
model_fit.save("arima_model.pkl")
plt.figure() создает новый график с указанным размером (ширина 12, высота 6).
pd.date_range() генерирует последовательность дат:
- start='2024-01-01' — начало прогноза (с 1 января 2024 года).
- periods=365 — количество шагов (дней), на которые делается прогноз.
- freq='D' — частота генерации дат (ежедневно).
plt.plot() строит линию прогноза на графике:
- future_dates — ось X (даты).
- forecast — ось Y (прогнозируемые значения).
- label='Улучшенный прогноз' — название линии на графике.
- color='blue' — цвет линии прогноза.
plt.legend() добавляет легенду на график, чтобы различать разные линии.
plt.grid() включает сетку на графике для лучшей читаемости.
plt.title("Прогноз с улучшенными параметрами") добавляет заголовок к графику
plt.show() отображает построенный график.
model_fit.save("arima_model.pkl") — это встроенный метод библиотеки statsmodels, который позволяет сохранить обученную модель в файл.
"arima_model.pkl" — это имя файла, в который сохраняется модель. Расширение .pkl указывает на использование формата pickle для сериализации.
Сохранение модели позволяет использовать ее позже без повторного обучения. Например, это может быть полезно для прогнозирования новых значений, а также для загрузки и тестирования на новых данных.
Финальный результат по продажам, ради которого мы и проводили всю процедуру:
model_fit.save("arima_model.pkl") — это встроенный метод библиотеки statsmodels, который позволяет сохранить обученную модель в файл.
"arima_model.pkl" — это имя файла, в который сохраняется модель. Расширение .pkl указывает на использование формата pickle для сериализации.
Сохранение модели позволяет использовать ее позже без повторного обучения. Например, это может быть полезно для прогнозирования новых значений, а также для загрузки и тестирования на новых данных.
Финальный результат по продажам, ради которого мы и проводили всю процедуру:
Хотим обратить внимание, что для прогнозирования 2024 года мы использовали данные за 2023 год. Прогнозирование оказалось точным, с незначительными отклонениями в пределах ±100 единиц товара.
Итоговый код:
python
Копировать код
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from pmdarima import auto_arima
from statsmodels.tsa.arima.model import ARIMA
# Загрузка данных
df = pd.read_csv("sales_data_year.csv")
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
df = df.sort_index()
series = df['units_sold']
series.plot(figsize=(10, 5))
plt.title("Продажи за год")
plt.show()
# Пример дифференцирования
series_diff = series.diff().dropna().diff().dropna()
result = adfuller(series)
print("ADF Statistic:", result[0])
print("p-value:", result[1])
fig, axes = plt.subplots(1, 2, figsize=(16, 4))
plot_acf(series_diff.dropna(), ax=axes[0])
plot_pacf(series_diff.dropna(), ax=axes[1])
plt.show()
stepwise_model = auto_arima(series, start_p=1, start_q=1,
max_p=5, max_q=5, m=7, # m=7 предполагает недельную сезонность (для ежедневных данных)
start_P=0, seasonal=False,
d=1, D=0, trace=True,
error_action='ignore',
suppress_warnings=True,
stepwise=True)
print(stepwise_model.summary())
# Предположим, ваш временной ряд это "series"
model = ARIMA(series, order=(0, 1, 1))
model_fit = model.fit()
print(model_fit.summary())
forecast = model_fit.forecast(steps=365)
# Построение графика
plt.figure(figsize=(12, 6))
future_dates = pd.date_range(start='2024-01-01', periods=365, freq='D')
plt.plot(future_dates, forecast, label='Улучшенный прогноз', color='blue')
plt.legend()
plt.grid()
plt.title("Прогноз с улучшенными параметрами")
plt.show()
model_fit.save("arima_model.pkl")
Вы можете скопировать весь итоговый код и вставить его в интерфейсе среды разработки, чтобы сразу запустить модель.
Заключение
С приходом искусственного интеллекта возможности автоматизации расширились до впечатляющих масштабов. Если Excel мы привыкли считать незаменимым при работе с данными, то ИИ выходит далеко за рамки привычных ограничений. Он способен анализировать огромные массивы информации, находить в них закономерности и точнее прогнозировать дальнейшие шаги. Именно это вдохновило меня на создание модели для прогнозирования продаж, которая станет надежным помощником в принятии решений, экономии сил и повышении эффективности работы.
Итоговый код:
python
Копировать код
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from pmdarima import auto_arima
from statsmodels.tsa.arima.model import ARIMA
# Загрузка данных
df = pd.read_csv("sales_data_year.csv")
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
df = df.sort_index()
series = df['units_sold']
series.plot(figsize=(10, 5))
plt.title("Продажи за год")
plt.show()
# Пример дифференцирования
series_diff = series.diff().dropna().diff().dropna()
result = adfuller(series)
print("ADF Statistic:", result[0])
print("p-value:", result[1])
fig, axes = plt.subplots(1, 2, figsize=(16, 4))
plot_acf(series_diff.dropna(), ax=axes[0])
plot_pacf(series_diff.dropna(), ax=axes[1])
plt.show()
stepwise_model = auto_arima(series, start_p=1, start_q=1,
max_p=5, max_q=5, m=7, # m=7 предполагает недельную сезонность (для ежедневных данных)
start_P=0, seasonal=False,
d=1, D=0, trace=True,
error_action='ignore',
suppress_warnings=True,
stepwise=True)
print(stepwise_model.summary())
# Предположим, ваш временной ряд это "series"
model = ARIMA(series, order=(0, 1, 1))
model_fit = model.fit()
print(model_fit.summary())
forecast = model_fit.forecast(steps=365)
# Построение графика
plt.figure(figsize=(12, 6))
future_dates = pd.date_range(start='2024-01-01', periods=365, freq='D')
plt.plot(future_dates, forecast, label='Улучшенный прогноз', color='blue')
plt.legend()
plt.grid()
plt.title("Прогноз с улучшенными параметрами")
plt.show()
model_fit.save("arima_model.pkl")
Вы можете скопировать весь итоговый код и вставить его в интерфейсе среды разработки, чтобы сразу запустить модель.
Заключение
С приходом искусственного интеллекта возможности автоматизации расширились до впечатляющих масштабов. Если Excel мы привыкли считать незаменимым при работе с данными, то ИИ выходит далеко за рамки привычных ограничений. Он способен анализировать огромные массивы информации, находить в них закономерности и точнее прогнозировать дальнейшие шаги. Именно это вдохновило меня на создание модели для прогнозирования продаж, которая станет надежным помощником в принятии решений, экономии сил и повышении эффективности работы.