
В электронной коммерции каждая минута простоя может обернуться не только потерей прибыли, но и утратой клиента, который, возможно, больше не вернется. Ошибки при оформлении корзины и процессе оплаты, а также длительная загрузка страниц способны подорвать доверие пользователей и негативно сказаться на конверсии. Восстановление утраченного трафика и лояльности клиентов зачастую обходится значительно дороже, чем предотвращение инцидента на ранних стадиях.
Поэтому важно внедрять проактивные меры, которые помогут минимизировать риски и обеспечить бесперебойную работу вашего ecommerce-проекта. Это включает в себя регулярный мониторинг системы, оптимизацию процессов и обучение команды, что в конечном итоге способствует повышению удовлетворенности клиентов и увеличению конверсии.
Поэтому важно внедрять проактивные меры, которые помогут минимизировать риски и обеспечить бесперебойную работу вашего ecommerce-проекта. Это включает в себя регулярный мониторинг системы, оптимизацию процессов и обучение команды, что в конечном итоге способствует повышению удовлетворенности клиентов и увеличению конверсии.
Проблемы техподдержки в большинстве ecommerce-проектов
В зрелых ecommerce-компаниях техподдержка часто организована по остаточному принципу, что приводит к серьезным проблемам. С увеличением числа цифровых точек отказа, таких как микросервисы, внешние API, фоновые задачи, платежные шлюзы, аналитика и логистика, риски сбоев только возрастают.
Нехватка ресурсов в нерабочее время
Большинство сбоев происходит вне рабочего времени, что создает дополнительные сложности. Авария на продакшене в 3 часа ночи может остаться незамеченной до утра, пока бизнес не "проснется" и не обнаружит падение продаж. Даже если сбой замечен, часто некому реагировать: команда спит, дежурного нет, а подрядчики работают по строгому графику.
Это приводит к 6-8 часам простоя, пустому трафику, потерянным заказам и ухудшению клиентского опыта.
Зависание бизнес-процессов из-за фоновых задач
В современных высоконагруженных проектах все процессы взаимосвязаны. Например, фоновая задача, отвечающая за синхронизацию заказов с CRM, может "зависнуть" на полдня. В результате менеджеры не видят новые заказы, пользователи не получают подтверждений, а служба доставки не получает заявки.
Эти проблемы подчеркивают необходимость более эффективной организации техподдержки, которая сможет оперативно реагировать на инциденты и минимизировать их влияние на бизнес.
В зрелых ecommerce-компаниях техподдержка часто организована по остаточному принципу, что приводит к серьезным проблемам. С увеличением числа цифровых точек отказа, таких как микросервисы, внешние API, фоновые задачи, платежные шлюзы, аналитика и логистика, риски сбоев только возрастают.
Нехватка ресурсов в нерабочее время
Большинство сбоев происходит вне рабочего времени, что создает дополнительные сложности. Авария на продакшене в 3 часа ночи может остаться незамеченной до утра, пока бизнес не "проснется" и не обнаружит падение продаж. Даже если сбой замечен, часто некому реагировать: команда спит, дежурного нет, а подрядчики работают по строгому графику.
Это приводит к 6-8 часам простоя, пустому трафику, потерянным заказам и ухудшению клиентского опыта.
Зависание бизнес-процессов из-за фоновых задач
В современных высоконагруженных проектах все процессы взаимосвязаны. Например, фоновая задача, отвечающая за синхронизацию заказов с CRM, может "зависнуть" на полдня. В результате менеджеры не видят новые заказы, пользователи не получают подтверждений, а служба доставки не получает заявки.
Эти проблемы подчеркивают необходимость более эффективной организации техподдержки, которая сможет оперативно реагировать на инциденты и минимизировать их влияние на бизнес.
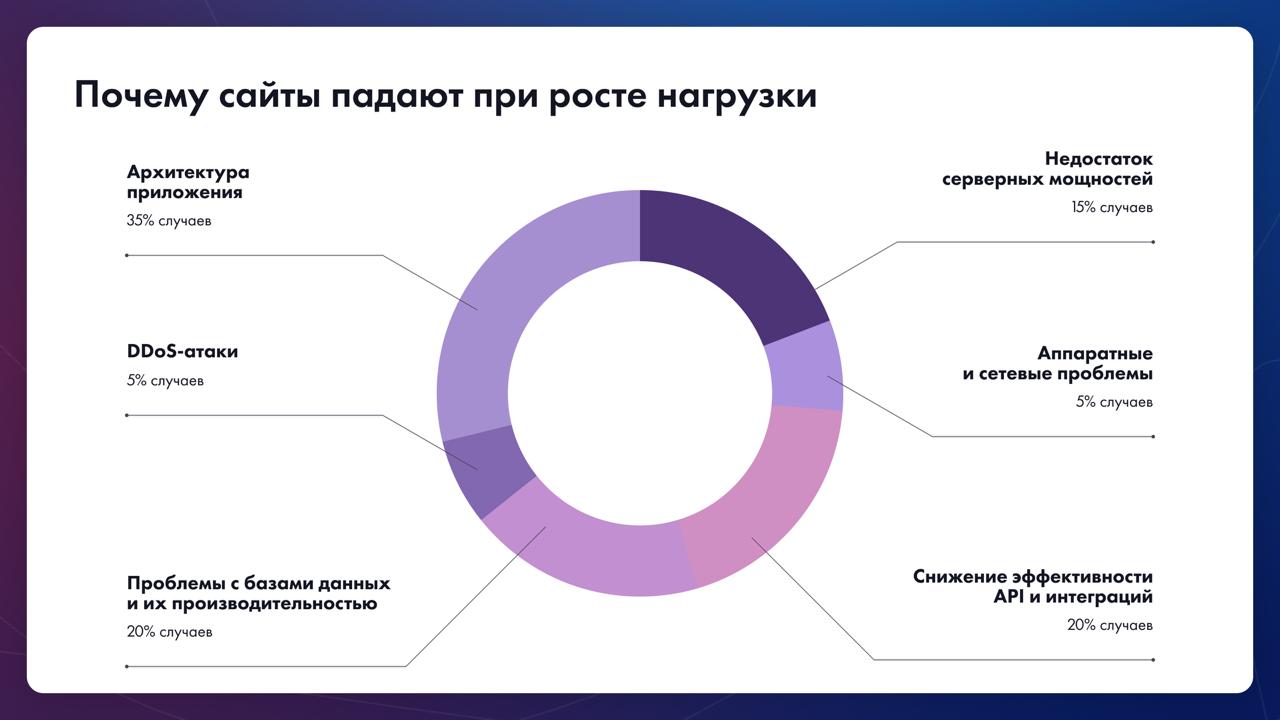
Цепная реакция сбоев в бизнес-процессах и недостатки техподдержки
Сбои в системе могут оставаться незамеченными на начальном этапе, но они вызывают цепную реакцию в бизнес-процессах, создавая хаос и стресс в операционных отделах. Время реакции на инциденты часто измеряется часами, а не минутами, что усугубляет ситуацию.
Причины медленной реакции на инциденты
В результате бизнес сталкивается с задержками, которые могли бы быть устранены за 5 минут при наличии эффективной инцидентной схемы и компетентной команды.
Недостаточный мониторинг критических точек
Даже в проектах с установленными системами мониторинга часто отсутствует полное покрытие критических этапов, таких как:
Без мониторинга этих ключевых этапов сбои остаются "невидимыми" до тех пор, пока пользователи не начнут жаловаться, что приводит к значительному ущербу.
Ограниченная поддержка
Традиционная техподдержка часто ориентирована на "ремонт" после сбоя, а не на его предотвращение. В ее задачи редко входят:
Эти недостатки подчеркивают необходимость пересмотра подхода к техподдержке, чтобы обеспечить более проактивное управление инцидентами и защиту бизнеса от потенциальных угроз.
Сбои в системе могут оставаться незамеченными на начальном этапе, но они вызывают цепную реакцию в бизнес-процессах, создавая хаос и стресс в операционных отделах. Время реакции на инциденты часто измеряется часами, а не минутами, что усугубляет ситуацию.
Причины медленной реакции на инциденты
- Отсутствие регламентов реагирования: Непонятные или неформализованные процедуры затрудняют быструю реакцию на проблемы.
- Недостаточная автоматизация: Без правильно настроенного алертинга и автоматизированных процессов обнаружение и устранение инцидентов занимает больше времени.
- Отсутствие 24/7-доступа: Невозможность доступа к ключевым сервисам и подсистемам в любое время суток задерживает решение проблем.
- Недостаток профильных специалистов: Отсутствие экспертов для устранения сложных инцидентов приводит к дополнительным задержкам.
В результате бизнес сталкивается с задержками, которые могли бы быть устранены за 5 минут при наличии эффективной инцидентной схемы и компетентной команды.
Недостаточный мониторинг критических точек
Даже в проектах с установленными системами мониторинга часто отсутствует полное покрытие критических этапов, таких как:
- Поиск товара, работа фильтров и добавление в корзину
- Создание заказа
- Прохождение оплаты
- Подтверждение доставки
Без мониторинга этих ключевых этапов сбои остаются "невидимыми" до тех пор, пока пользователи не начнут жаловаться, что приводит к значительному ущербу.
Ограниченная поддержка
Традиционная техподдержка часто ориентирована на "ремонт" после сбоя, а не на его предотвращение. В ее задачи редко входят:
- Анализ и защита от DDoS-атак, SQL-инъекций и других угроз
- Тестирование отказоустойчивости под пиковые нагрузки (например, во время распродаж)
- Контроль за критическим путем пользователя — от захода на сайт до оформления заказа
Эти недостатки подчеркивают необходимость пересмотра подхода к техподдержке, чтобы обеспечить более проактивное управление инцидентами и защиту бизнеса от потенциальных угроз.
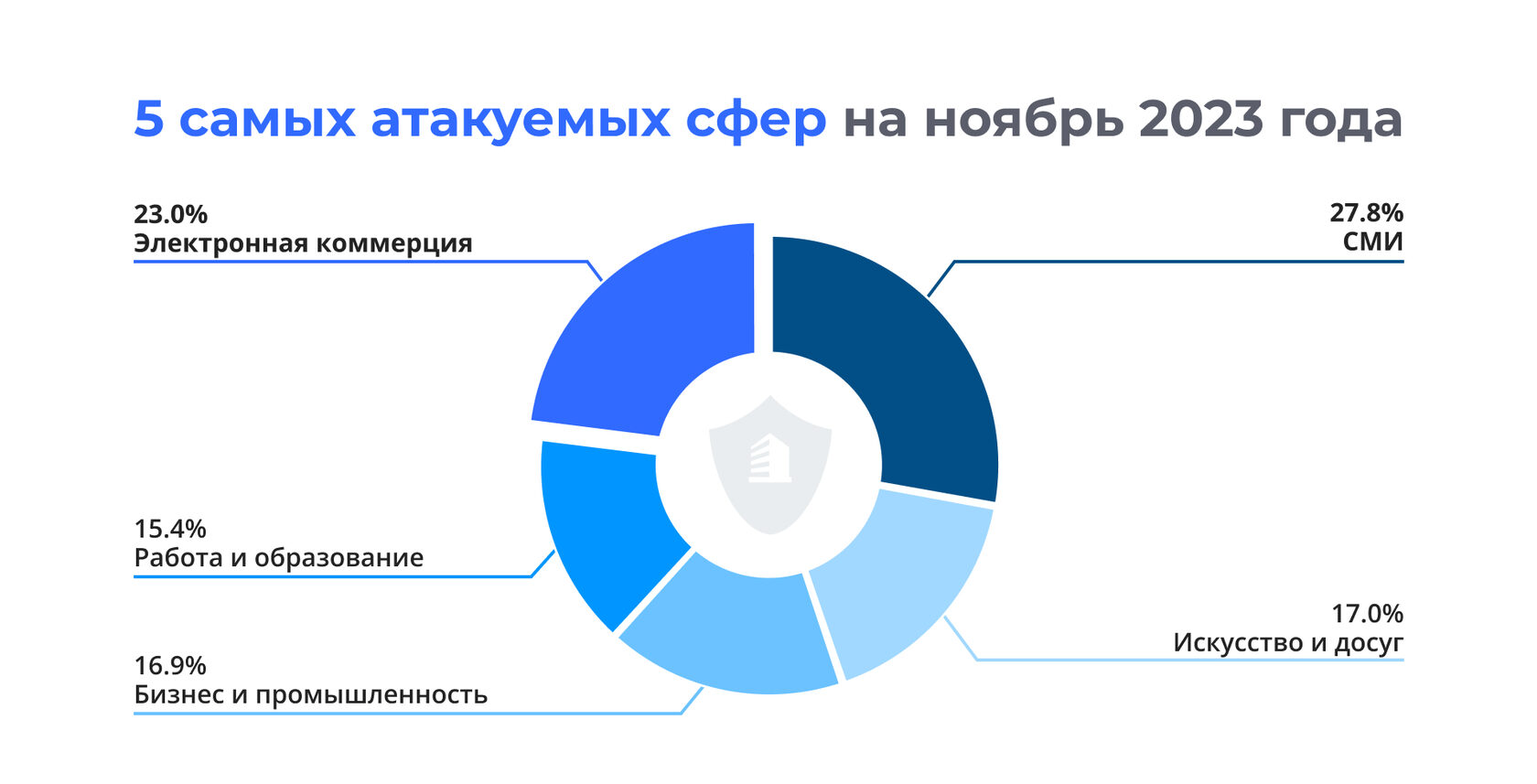
Уязвимость бизнеса и необходимость инцидентной поддержки
Даже при наличии техподдержки бизнес остается уязвимым к типичным угрозам и перегрузкам, особенно в периоды активного спроса. Это подчеркивает важность инцидентной поддержки для обеспечения стабильной работы и защиты репутации компании.
Что такое инцидентная поддержка?
ИТ-инцидент — это любое отклонение от стандартной работы сервиса, которое приводит к нарушению его доступности или качества. Примеры инцидентов включают сбой в работе CRM-системы, замедление обработки данных или ошибки авторизации пользователей. Каждый инцидент требует немедленного реагирования, чтобы минимизировать его влияние на бизнес-процессы.
Почему инциденты неизбежны?
Инциденты — это не вопрос "если", а "когда". Важно, насколько быстро на них отреагируют и насколько эффективно их решат. Для бизнеса это уже не просто техническая задача, а вопрос сохранения репутации, клиентской лояльности и прибыли.
Создание инцидентной поддержки: плюсы и минусы
Создание собственной инцидентной поддержки может быть дорогостоящим и не всегда оправданным шагом. Чтобы обеспечить круглосуточный режим работы, необходимо минимум четыре дежурных специалиста, что приводит к постоянным расходам на зарплаты, обучение, контроль качества и бесперебойную работу.
Аутсорсинг инцидентной поддержки
В связи с вышеописанными трудностями все больше компаний передают инцидентную поддержку на аутсорсинг профессиональным командам. Эти команды уже выстроили эффективные процессы, умеют быстро реагировать на инциденты и не тратят время на раскачку. Это позволяет бизнесу сосредоточиться на своих ключевых задачах, минимизируя риски и обеспечивая стабильность работы.
Даже при наличии техподдержки бизнес остается уязвимым к типичным угрозам и перегрузкам, особенно в периоды активного спроса. Это подчеркивает важность инцидентной поддержки для обеспечения стабильной работы и защиты репутации компании.
Что такое инцидентная поддержка?
ИТ-инцидент — это любое отклонение от стандартной работы сервиса, которое приводит к нарушению его доступности или качества. Примеры инцидентов включают сбой в работе CRM-системы, замедление обработки данных или ошибки авторизации пользователей. Каждый инцидент требует немедленного реагирования, чтобы минимизировать его влияние на бизнес-процессы.
Почему инциденты неизбежны?
Инциденты — это не вопрос "если", а "когда". Важно, насколько быстро на них отреагируют и насколько эффективно их решат. Для бизнеса это уже не просто техническая задача, а вопрос сохранения репутации, клиентской лояльности и прибыли.
Создание инцидентной поддержки: плюсы и минусы
Создание собственной инцидентной поддержки может быть дорогостоящим и не всегда оправданным шагом. Чтобы обеспечить круглосуточный режим работы, необходимо минимум четыре дежурных специалиста, что приводит к постоянным расходам на зарплаты, обучение, контроль качества и бесперебойную работу.
Аутсорсинг инцидентной поддержки
В связи с вышеописанными трудностями все больше компаний передают инцидентную поддержку на аутсорсинг профессиональным командам. Эти команды уже выстроили эффективные процессы, умеют быстро реагировать на инциденты и не тратят время на раскачку. Это позволяет бизнесу сосредоточиться на своих ключевых задачах, минимизируя риски и обеспечивая стабильность работы.
Как устроен процесс поддержки: 6 шагов от анализа до отчета
Инцидентная поддержка 360° — это не просто набор инструментов, а четко выстроенный процесс, который начинается с подготовки и включает непрерывный цикл мониторинга, реагирования и совершенствования. Вот как это работает шаг за шагом:
1. Предварительный аудит
На начальном этапе проводится аудит текущего состояния системы, включая серверную инфраструктуру и бизнес-логику. Проверяются настройки бэкапов, критические узлы и потенциальные точки отказа. Результатом становится карта рисков и список уязвимостей, которые необходимо устранить до запуска постоянного мониторинга.
2. Определение метрик
Совместно с клиентом определяются ключевые метрики для отслеживания. Это не только технические показатели (нагрузка, ошибки, аптайм), но и бизнес-показатели, такие как количество заказов, время отклика корзины и успешные оплаты. Такой подход позволяет видеть не только технические проблемы, но и их влияние на бизнес.
3. Настройка мониторинга и бэкапов
Подключаются системы мониторинга, где все метрики собираются в дашбордах, и настраиваются алерты с приоритетами. Параллельно настраивается резервное копирование данных с возможностью дублирования в защищенное хранилище.
4. Обеспечение безопасности
Проводится аудит безопасности, включая проверку SSL-сертификатов, обновление зависимостей и настройку WAF и DDoS-защиты. Включаются системы обнаружения аномалий, что позволяет предотвратить атаки до их реализации.
5. Реакция на инциденты
При фиксации инцидента срабатывает цепочка реагирования: дежурный инженер получает алерт, проводится анализ и диагностика, устраняется проблема, уведомляется команда клиента, и ведется журнал инцидента. SLA по реакции составляет до 15 минут, независимо от времени суток.
6. Отчет и рекомендации
После инцидента или по итогам месяца формируется отчет о стабильности, фиксирующий причины сбоев, время восстановления и рекомендации по улучшению. Это позволяет бизнесу видеть общую картину и принимать обоснованные решения.
Какие метрики и риски покрывает инцидентная поддержка
Инцидентная поддержка 360° обеспечивает системный контроль над всей цифровой экосистемой, включая как технические, так и бизнес-критичные показатели. Вот основные метрики, которые мониторятся в режиме 24/7:
Эти метрики позволяют команде поддержки выявлять и устранять проблемы до того, как они станут кризисом, обеспечивая стабильность и эффективность бизнеса.
Инцидентная поддержка 360° — это не просто набор инструментов, а четко выстроенный процесс, который начинается с подготовки и включает непрерывный цикл мониторинга, реагирования и совершенствования. Вот как это работает шаг за шагом:
1. Предварительный аудит
На начальном этапе проводится аудит текущего состояния системы, включая серверную инфраструктуру и бизнес-логику. Проверяются настройки бэкапов, критические узлы и потенциальные точки отказа. Результатом становится карта рисков и список уязвимостей, которые необходимо устранить до запуска постоянного мониторинга.
2. Определение метрик
Совместно с клиентом определяются ключевые метрики для отслеживания. Это не только технические показатели (нагрузка, ошибки, аптайм), но и бизнес-показатели, такие как количество заказов, время отклика корзины и успешные оплаты. Такой подход позволяет видеть не только технические проблемы, но и их влияние на бизнес.
3. Настройка мониторинга и бэкапов
Подключаются системы мониторинга, где все метрики собираются в дашбордах, и настраиваются алерты с приоритетами. Параллельно настраивается резервное копирование данных с возможностью дублирования в защищенное хранилище.
4. Обеспечение безопасности
Проводится аудит безопасности, включая проверку SSL-сертификатов, обновление зависимостей и настройку WAF и DDoS-защиты. Включаются системы обнаружения аномалий, что позволяет предотвратить атаки до их реализации.
5. Реакция на инциденты
При фиксации инцидента срабатывает цепочка реагирования: дежурный инженер получает алерт, проводится анализ и диагностика, устраняется проблема, уведомляется команда клиента, и ведется журнал инцидента. SLA по реакции составляет до 15 минут, независимо от времени суток.
6. Отчет и рекомендации
После инцидента или по итогам месяца формируется отчет о стабильности, фиксирующий причины сбоев, время восстановления и рекомендации по улучшению. Это позволяет бизнесу видеть общую картину и принимать обоснованные решения.
Какие метрики и риски покрывает инцидентная поддержка
Инцидентная поддержка 360° обеспечивает системный контроль над всей цифровой экосистемой, включая как технические, так и бизнес-критичные показатели. Вот основные метрики, которые мониторятся в режиме 24/7:
- Доступность сервисов: Контроль доступности сайта, мобильного приложения, админки и API.
- Ресурсы и производительность: Нагрузочные метрики, такие как загрузка CPU, RAM и скорость отклика страниц.
- Состояние БД и приложений: Мониторинг медленных SQL-запросов и зависаний в микросервисах.
- Безопасность и сертификаты: Проверка сроков действия SSL-сертификатов и подозрительной активности.
- Критический путь: Отслеживание полного цикла от захода клиента до подтверждения покупки.
- Интеграции: Мониторинг внешних систем, таких как ERP и WMS.
- Аномалии поведения: Выявление отклонений от нормы, таких как внезапное падение заказов или рост ошибок.
Эти метрики позволяют команде поддержки выявлять и устранять проблемы до того, как они станут кризисом, обеспечивая стабильность и эффективность бизнеса.